- Call Us: +351910255068
- Email us:

Uma arquitetura moderna e flexível
Diagrama da arquitetura do sistema
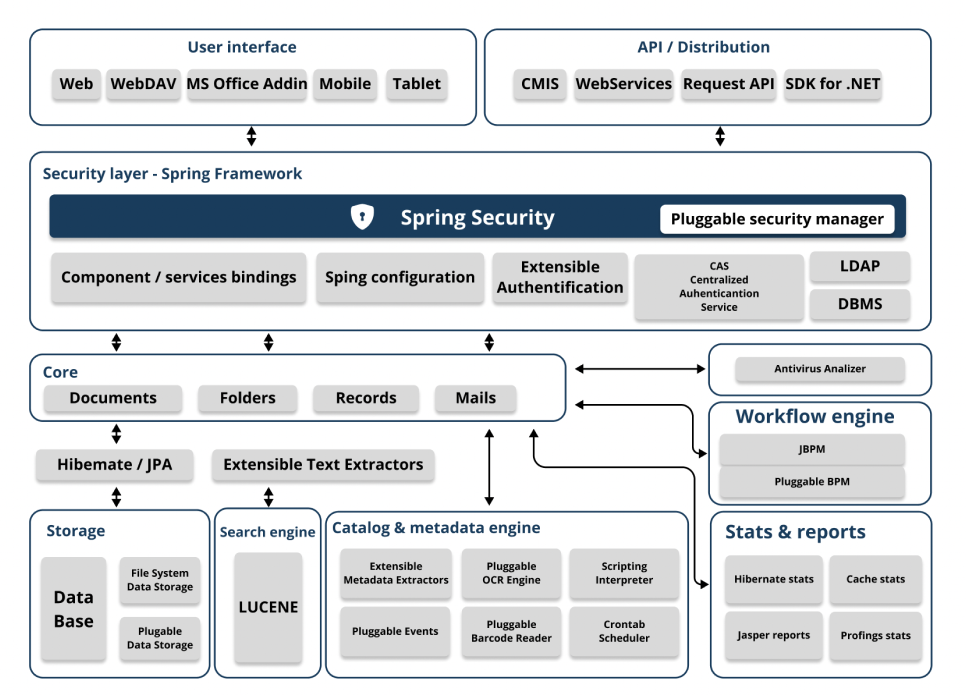
Interface do utilizador
Permite o acesso à aplicação através de um navegador Web, bem como uma interface específica para dispositivos móveis, suplementos para o Microsoft Office ou o protocolo FTP, entre outros.
API
API abrangente através de serviços Web RESTful com cerca de 500 tipos de pedidos diferentes e que pode ser utilizada como ponto de integração com aplicações de terceiros.
Para o desenvolvimento de aplicações, estão disponíveis SDKs (Software Development Kits) para Java e .NET, que permitem um acesso fácil à API do OpenKM.
Camada de segurança
O OpenKM é uma aplicação Java EE que utiliza o Spring Framework. O módulo mais relevante é a camada de segurança - Spring Security - que centraliza a gestão do acesso dos utilizadores com base nas suas credenciais. O controlo de segurança encontra-se num módulo AccessManager, que implementa a lógica de avaliação de segurança na aplicação. A arquitetura Java EE implementada no OpenKM permite uma lógica de segurança personalizada.
A autenticação pode ser efectuada com LDAP, através da própria base de dados do OpenKM, ou através de módulos específicos (e.g., OAUTH).
Núcleo
O OpenKM Core centraliza e implementa a lógica de gestão e processamento de diferentes tipos de objectos que são armazenados no repositório. Estes objectos são do tipo documento, pasta, emails e registos, bem como a combinação de estruturas de metadados.
Mecanismo de fluxo de trabalho
O OpenKM incorpora por padrão o mecanismo de workflow JBPM. A arquitetura Java EE implementada no OpenKM permite trabalhar - conectar - com outros mecanismos de Workflows de forma transparente.
Armazenar
O OpenKM usa Hibernate para mapeamento de dados OMR (Object Relation Mapping) e suporta diferentes bases de dados relacionais (DBMS) como o PostgreSQL, MySQL, Oracle, MS SQL Server, DB2 entre outros. Toda a camada de metadados é armazenada em base de dados DBMS. Os objetos binários (documentos), são armazenados no sistema de arquivos, em base de dados ou numa implementação específica do DataStore. Graças à arquitetura Java EE implementada no OpenKM, podem-se criar DataStore específicos.
Motor de busca
O OpenKM usa Lucene como mecanismo de pesquisa. Todos os objetos que o OpenKM trabalha, sejam binários ou não, são indexados pelo motor de busca. Os objetos binários, como documentos do Microsoft Office, PDFs ou imagens, etc., são adicionados a uma fila de indexação.
Antes de serem processados pelo Lucene, os documentos são analisados por extratores de texto (Text Extractors). Por exemplo, no caso de imagens, elas são processadas por um mecanismo de OCR para identificação de strings de texto, que serão utilizadas durante o processo de indexação do Lucene. Os resultados do mecanismo de pesquisa são filtrados pelo Security Manager. Os utilizadores só podem acessar as informações para as quais têm privilégios.
Catálogo e metadados
Barcode Engine permite identificar e ler códigos de barras nos documentos. A arquitetura Java EE implementada no OpenKM permite ampliar a capacidade de leitura e processamento de formatos de código de barras.
O OpenKM está integrado com vários motores OCR open source (ex: Tesseract, Cuneiform) mas também aplicações comerciais (ex: Abby, Kofax, Cognitive, entre outros).
Scripting - Shell Bean - aliado ao sistema de eventos, smart tasks, task scheduler (Crontab) e relatórios (Jasper Reports) permitem planear, implementar e controlar o processo de captura automática de metadados e automatizar processos complexos de forma totalmente transparente para o utilizador.
Antivírus
OpenKM pode ser integrado com a maioria dos antivírus. Todos os objetos binários são processados pelo mecanismo antivírus, garantindo a integridade do repositório e a segurança dos utilizadores na documentação de uso diário.
Estatísticas e relatórios
O sistema de estatísticas e relatórios OpenKM põe nas mãos dos administradores uma poderosa fonte de informação para controlar o estado da aplicação. Assim, pode ser analisado um conjunto de valores: quanto ao uso da camada Hibernate, as métricas de cache de segundo nível e métodos referentes à API e ao núcleo.
Essas informações auxiliam na tomada de decisões para estabelecer os valores ótimos para os objetos na cache de segundo nível, a parametrização dos recursos utilizados pelo SGBD e como eles são utilizados, antecipando problemas que possam surgir no futuro, por exemplo a nível de hardware, entre outros.
Contate-Nos
Questões gerais
-
-
E-mail

-
Horário de Atendimento
Segunda à Sexta das 09:00 às 18:00
-
Sede da Empresa
Edifício Portela Business Center, Estrada da Portela, Nº 5 (Lote 4), 3 piso, Escritório 9, Lisbon - Portugal
-
OpenKM em todo o mundo
Brasil: www.openkm.com.br
Ecuador: www.openkm.ec
França: www.openkm.fr
Alemanha: www.openkm.de
Grécia: www.openkm.gr
Hungria: www.openkm.hu
Indonésia: www.openkm.id
Itália: www.openkm.it
Malásia: www.openkm.my
México: www.openkm-mexico.com
Oriente Médio: www.openkm.me
Norte da África: www.openkm.me
Paraguai: www.openkm.com.py
Polônia: www.openkm.pl
Romênia: www.openkm.ro
Sérvia: www.openkm.rs
Espanha: www.openkm.com
EUA: www.openkm.us
Preferências de cookies
Estritamente necessários Necessários para o funcionamento do site. Não podem ser desativados.
Analíticos Ajudam-nos a compreender como os visitantes interagem com o site.
Marketing Utilizados para mostrar anúncios relevantes e monitorizar campanhas.